
 O Google DeepMind revelou o DiffusionGemma, um novo modelo de inteligência artificial de código aberto que promete transformar a forma como o conteúdo escrito é processado localmente. A grande inovação deste sistema assenta no abandono da tradicional geração sequencial de texto, avançando para um método inovador de processamento em paralelo. Conforme detalhado no blogue oficial do Google, a novidade consegue alcançar uma velocidade substancialmente superior à das soluções anteriores da mesma família de produtos.
O Google DeepMind revelou o DiffusionGemma, um novo modelo de inteligência artificial de código aberto que promete transformar a forma como o conteúdo escrito é processado localmente. A grande inovação deste sistema assenta no abandono da tradicional geração sequencial de texto, avançando para um método inovador de processamento em paralelo. Conforme detalhado no blogue oficial do Google, a novidade consegue alcançar uma velocidade substancialmente superior à das soluções anteriores da mesma família de produtos.
O que muda com a geração paralela de texto
Ao contrário dos modelos autorregressivos tradicionais, que constroem as frases palavra por palavra, ou seja, token por token, o DiffusionGemma adota uma abordagem inspirada nas técnicas de difusão habitualmente utilizadas em ferramentas de inteligência artificial para imagem. O modelo trabalha através de um processo de refinamento que gera blocos completos de 256 tokens em simultâneo. Esta metodologia, focada no conceito de remoção de ruído, permite que a eficácia da produção textual seja significativamente otimizada.
Com esta nova estrutura de funcionamento, o modelo da família Gemma consegue atingir velocidades de processamento até quatro vezes superiores às das versões que o antecederam. Esta característica torna o ecossistema ideal para lidar com tarefas complexas não lineares, como a edição de texto em linha, gráficos matemáticos de alta precisão e o próprio sequenciamento molecular.
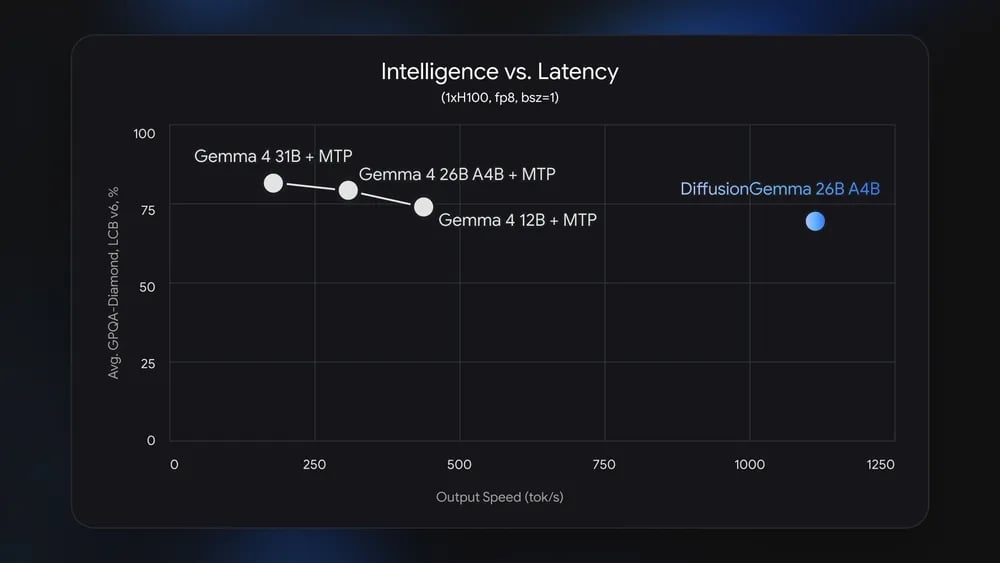
Desempenho local com hardware de topo
No campo técnico, o DiffusionGemma apresenta-se como um modelo baseado na arquitetura Mixture of Experts (MoE) com um total de 26 mil milhões de parâmetros, dos quais 3,8 mil milhões são ativados dinamicamente durante cada inferência. Em termos práticos de velocidade e rendimento, quando colocado a correr localmente em computadores equipados com placas gráficas de alto desempenho, os resultados obtidos são muito promissores.
O sistema foi testado em plataformas que utilizam hardware gráfico avançado e demonstrou uma capacidade computacional muito elevada:
- Numa placa da linha NVIDIA H100, o modelo consegue produzir entre 700 a 1.000 tokens por segundo.
- O desempenho mantém-se igualmente elevado quando executado noutros componentes de consumo de topo, tais como a placa RTX 5090.
Apesar deste rendimento assinalável em cenários locais, a técnica de difusão aplicada à vertente textual ainda apresenta desafios particulares, como a ocorrência de pequenos erros discretos no texto final. Esta limitação técnica faz com que o modelo seja considerado menos fiável para implementações massivas assentes na nuvem, encontrando a sua verdadeira utilidade no processamento local, onde consegue extrair o máximo partido do poder computacional disponível na própria máquina. O DiffusionGemma já se encontra disponível para descarregamento na plataforma Hugging Face, distribuído sob a licença de código aberto Apache 2.0.
(TT)