
 A introdução de ferramentas de Machine Learning nos sistemas de deteção de anomalias permite às organizações tomar decisões mais eficazes. Quais os benefícios? Que perfil de empresas poderá usar esta solução? Como atuam os especialista de Data Science em caso de fraude? Luís Vicente, Big Data & Data Science Director na Xpand IT, esclarece.
A introdução de ferramentas de Machine Learning nos sistemas de deteção de anomalias permite às organizações tomar decisões mais eficazes. Quais os benefícios? Que perfil de empresas poderá usar esta solução? Como atuam os especialista de Data Science em caso de fraude? Luís Vicente, Big Data & Data Science Director na Xpand IT, esclarece.
Quais os benefícios mais evidentes de Machine Learning na deteção de fraudes?
Machine Learning, quando aplicado a sistemas de deteção de anomalias, potencia a identificação de problemas emergentes com maior rapidez e eficácia, evitando que este se torne num problema de maior dimensão e severidade. As empresas dispõem de volumes de dados cada vez mais elevados, que tornam impossível análises manuais. É aqui que Machine Learning, que combina métodos estatísticos com a capacidades de computação sem paralelo, pode fomentar a identificação de padrões nos dados de forma rápida.
A grande mais-valia de Machine Learning está não só na capacidade de criar novas formas de analisar e extrair valor dos dados, mas também no reforço de capacidade e relevância sobre métodos existentes, assegurando organizações mais eficazes.
Quais os benefícios do ponto de vista do consumidor? Como é que um modelo de Machine Learning pode ser útil a prever situações adversas?
Um modelo de Machine Learning pode correr 24/7, tomando ações de prevenção ou emitindo alertas de potenciais anomalias. Estes processos automáticos podem ser implementados com targets de eficiência muito superiores aos possíveis com humanos, permitindo deteção de anomalias em ordens de grandeza inferiores a um segundo, quando, por norma, uma reação ainda é eficaz – pense-se, por exemplo, na deteção de um acesso indevido a um sistema ou uma transação de crédito fraudulenta, cuja reação em um segundo terá um resultado bem diferente de uma reação ao fim de uma hora ou um dia.
Outra vantagem é a capacidade de aprendizagem automática de um processo de Machine Learning. Quando trabalhamos com sistemas cuja anomalia também pode variar e ter diferentes expressões ao longo do tempo, um modelo de Machine Learning pode realizar aprendizagem continua, através de feedback, ou retro-alimentação, nas suas previsões e usa este feedback para ir continuamente melhorando a sua performance de modo a adaptar-se à evolução do sistema e dados que o alimentam ao longo do seu tempo de vida. Isto significa que o sistema base é um produto vivo que evolui rapidamente e sem depender de mecanismos, tendencialmente, mais morosos.
A automatização destas tarefas permite aos analistas a possibilidade de se focarem em tarefas com maior relevância e de maior valor para a organização.

Qual o perfil das organizações que tira maior partido de uma solução deste tipo?
A disciplina de deteção de anomalias é muito abrangente, sendo que todos os setores de atividade podem tirar partido deste tipo de soluções. Dando alguns exemplos concretos:
- Deteção de fraude através de dados de transações, por exemplo no setor bancário;
- Deteção de anomalias de maquinaria, de modo a antecipar falhas e antecipar manutenção reduzindo downtimes e custos de reparação associados, traz uma grande vantagem para o setor de indústrias transformadoras;
- Identificação de eventos com base em dados de sensores, por exemplo identificação de uma fuga num circuito de água, com um claro benefício em empresas de utilities.
Dada a abrangência de soluções e setores de atividade, existe uma abordagem comum a projetos deste tipo, ou cada caso é um caso?
De facto, a disciplina de deteção de anomalias é complexa dado que, como anteriormente indicado, uma anomalia pode ter expressões, objetivos de negócio, formas de deteção e atuação diferentes e, apesar de, comummente ser difícil reaproveitar soluções, existem troncos de trabalho comuns que podem beneficiar qualquer iniciativa deste tipo. Por exemplo, uma iniciativa de DS beneficia de um primeiro passo focado na análise de viabilidade do projeto. Neste podem ser estruturados 3 principais vetores de análise:
- Componente de negócio: definição de objetivos e métricas de negócio que se pretende atingir;
- Componente dos dados: análise dos dados disponíveis e sua qualidade, de modo a compreender se os objetivos são alcançáveis;
- Critérios de sucesso ou interrupção: Definição de critérios que permitam interromper as iterações do projeto, mediante o atingimento do sucesso, ou a incapacidade de os obter.
Em que se diferencia a proposta de valor da Xpand IT?
Sendo uma empresa de consultoria com especialização em Data Science, tem na sua história uma longa lista de iniciativas de diferentes disciplinas relacionadas com Data Science, e em vários setores de atividade. Fruto desta experiência, desenvolve uma metodologia própria, designada XP4DS, que tenta reduzir e controlar a incerteza natural de iniciativas de Data Science, e que se baseia em metodologias Agile bem sedimentadas em IT (e.g. Scrum, XP), enfrentando menor resistência e maior flexibilidade.
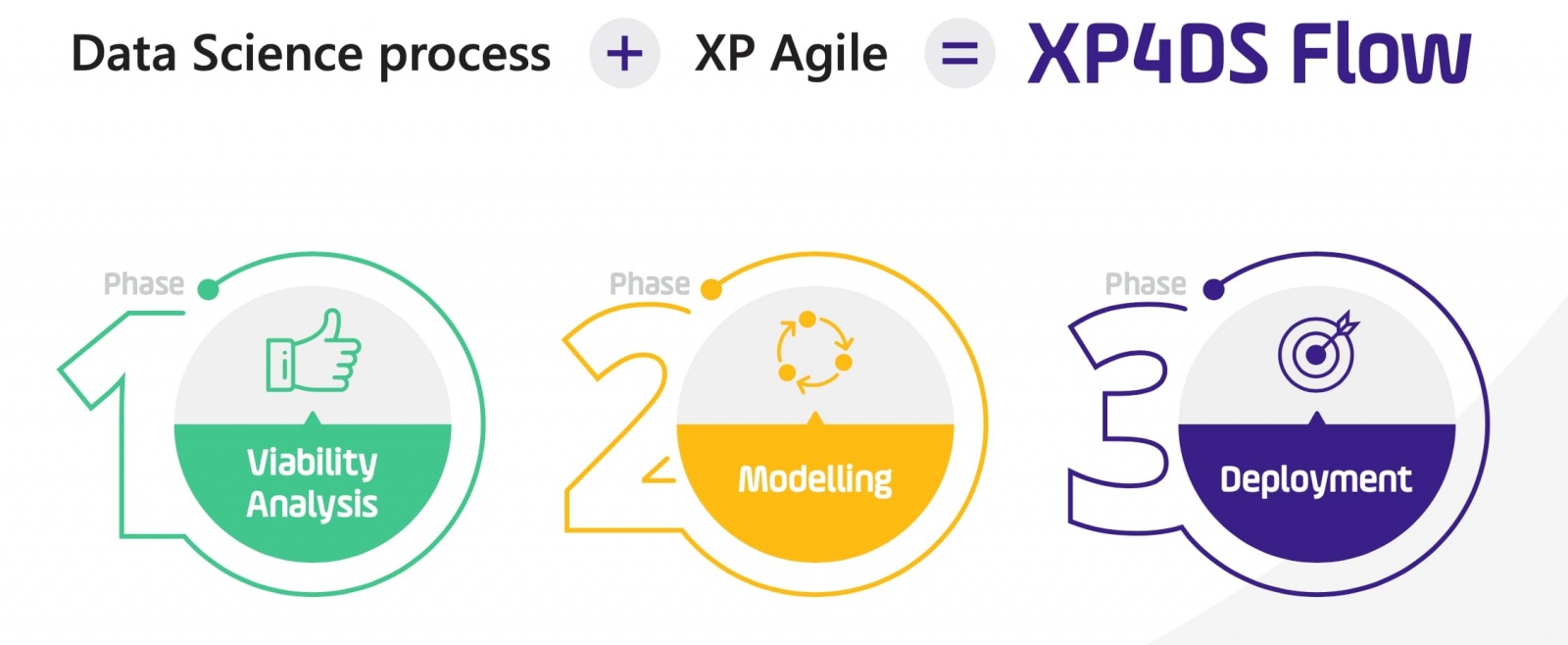
Esta metodologia é composta por três fases, sendo a primeira correspondente à análise de viabilidade que apresenta algumas características idênticas às anteriormente referidas.
Na 2ª fase, os Data Scientists começam o trabalho mais conhecido de modelação, que engloba exploração e preparação dos dados, desenvolvimento do modelo e, finalmente, testes e validação. Este é um processo iterativo onde se testam diferentes métodos e estratégias com o objetivo de atingir os critérios de sucesso definidos na fase anterior.
Após ter sido escolhido um modelo que cumpre os requisitos de negócio, entra-se na fase de produtização, instalação e monitorização, que implica todo o planeamento sobre a infraestrutura de suporte ao projeto, deploy e respetivo escalonamento e orquestração. Para além destes passos, e reconhecendo a importância de supervisão de modelos de Machine Learning, é também assegurado que as soluções Xpand IT dispõem de mecanismos de monitorização e deteção de desvios, que espoletam ações para combater problemas de perda de performance e manter o modelo válido ao longo do tempo.
(Exameinformatica)